
))
AI Magic: Shipping 1000s of successful products with no managers and a team of 12 — Jeremy Howard of Answer.ai
Manage episode 434592706 series 3451473
コンテンツは swyx & Alessio によって提供されます。エピソード、グラフィック、ポッドキャストの説明を含むすべてのポッドキャスト コンテンツは、swyx & Alessio またはそのポッドキャスト プラットフォーム パートナーによって直接アップロードされ、提供されます。誰かがあなたの著作物をあなたの許可なく使用していると思われる場合は、ここで概説されているプロセスに従うことができますhttps://ja.player.fm/legal。
Disclaimer: We recorded this episode ~1.5 months ago, timing for the FastHTML release. It then got bottlenecked by Llama3.1, Winds of AI Winter, and SAM2 episodes, so we’re a little late. Since then FastHTML was released, swyx is building an app in it for AINews, and Anthropic has also released their prompt caching API.
Remember when of coined the GPU Rich vs GPU Poor war? (if not, see our pod with him). The idea was that if you’re GPU poor you shouldn’t waste your time trying to solve GPU rich problems (i.e. pre-training large models) and are better off working on fine-tuning, optimized inference, etc.
Jeremy Howard (see our “End of Finetuning” episode to catchup on his background) and Eric Ries founded Answer.AI to do exactly that: “Practical AI R&D”, which is very in-line with the GPU poor needs. For example, one of their first releases was a system based on FSDP + QLoRA that let anyone train a 70B model on two NVIDIA 4090s. Since then, they have come out with a long list of super useful projects (in no particular order, and non-exhaustive):
FSDP QDoRA: this is just as memory efficient and scalable as FSDP/QLoRA, and critically is also as accurate for continued pre-training as full weight training.
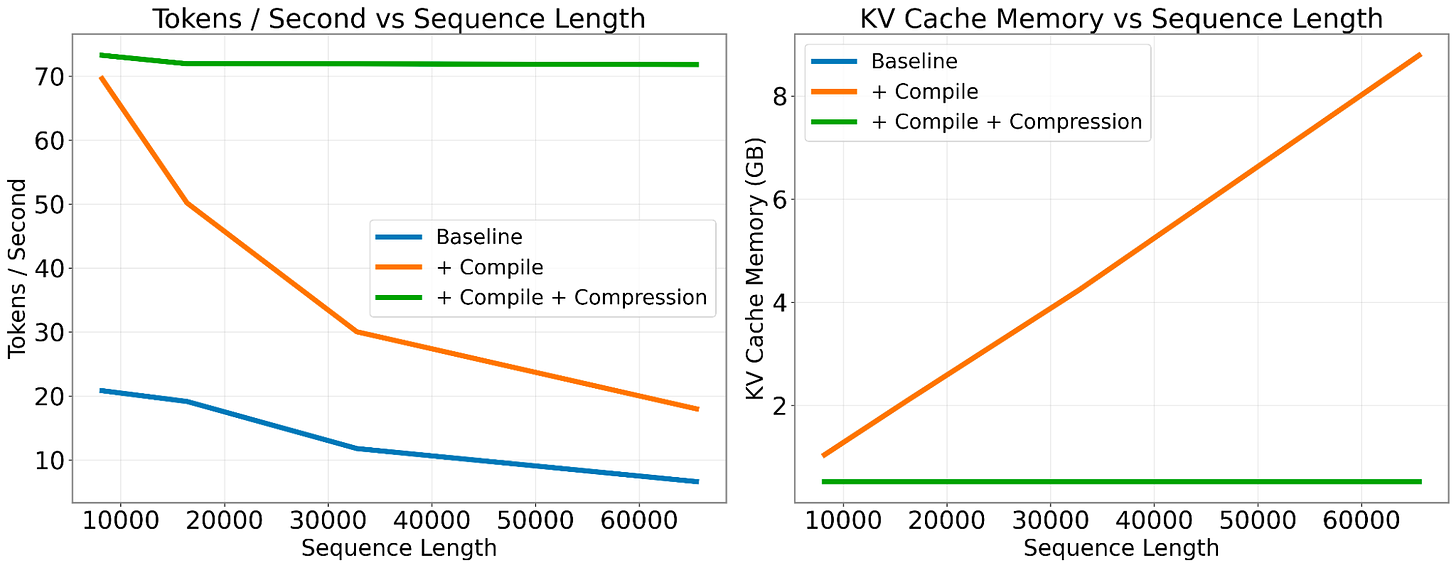
Cold Compress: a KV cache compression toolkit that lets you scale sequence length without impacting speed.
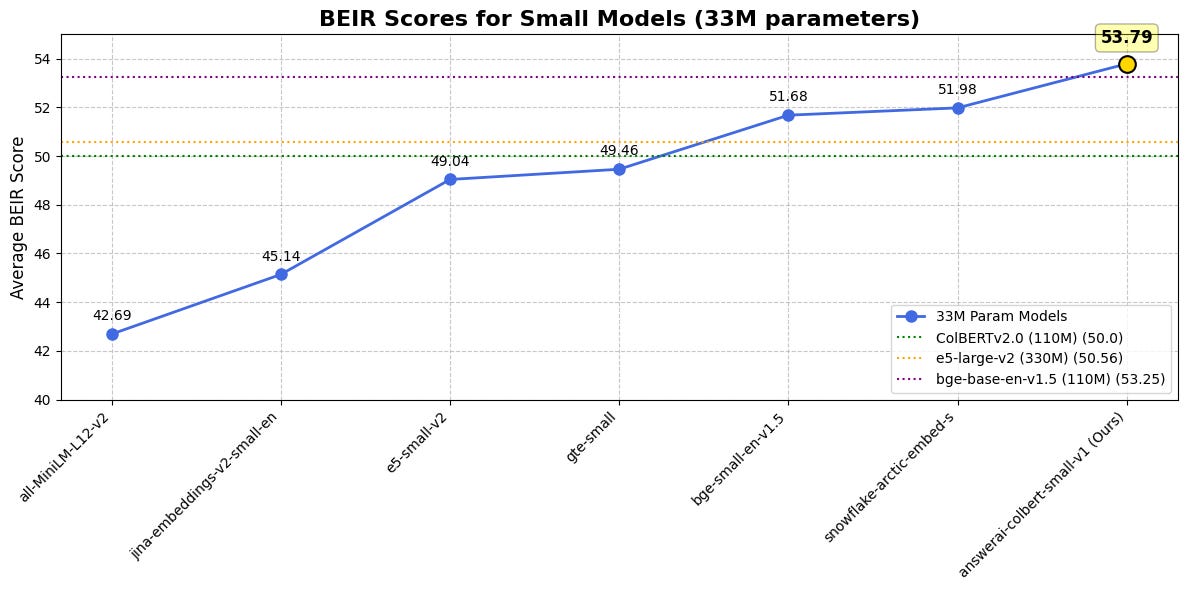
colbert-small: state of the art retriever at only 33M params
JaColBERTv2.5: a new state-of-the-art retrievers on all Japanese benchmarks.
gpu.cpp: portable GPU compute for C++ with WebGPU.
Claudette: a better Anthropic API SDK.
They also recently released FastHTML, a new way to create modern interactive web apps. Jeremy recently released a 1 hour “Getting started” tutorial on YouTube; while this isn’t AI related per se, but it’s close to home for any AI Engineer who are looking to iterate quickly on new products:
In this episode we broke down 1) how they recruit 2) how they organize what to research 3) and how the community comes together.
At the end, Jeremy gave us a sneak peek at something new that he’s working on that he calls dialogue engineering:
So I've created a new approach. It's not called prompt engineering. I'm creating a system for doing dialogue engineering. It's currently called AI magic. I'm doing most of my work in this system and it's making me much more productive than I was before I used it.
He explains it a bit more ~44:53 in the pod, but we’ll just have to wait for the public release to figure out exactly what he means.
Timestamps
[00:00:00] Intro by Suno AI
[00:03:02] Continuous Pre-Training is Here
[00:06:07] Schedule-Free Optimizers and Learning Rate Schedules
[00:07:08] Governance and Structural Issues within OpenAI and Other AI Labs
[00:13:01] How Answer.ai works
[00:23:40] How to Recruit Productive Researchers
[00:27:45] Building a new BERT
[00:31:57] FSDP, QLoRA, and QDoRA: Innovations in Fine-Tuning Large Models
[00:36:36] Research and Development on Model Inference Optimization
[00:39:49] FastHTML for Web Application Development
[00:46:53] AI Magic & Dialogue Engineering
[00:52:19] AI wishlist & predictions
Show Notes
Previously on Latent Space: The End of Finetuning, NeurIPS Startups
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, partner and CTO-in-Residence at Decibel Partners, and I'm joined by my co-host Swyx, founder of Smol AI.
Swyx [00:00:14]: And today we're back with Jeremy Howard, I think your third appearance on Latent Space. Welcome.
Jeremy [00:00:19]: Wait, third? Second?
Swyx [00:00:21]: Well, I grabbed you at NeurIPS.
Jeremy [00:00:23]: I see.
Swyx [00:00:24]: Very fun, standing outside street episode.
Jeremy [00:00:27]: I never heard that, by the way. You've got to send me a link. I've got to hear what it sounded like.
Swyx [00:00:30]: Yeah. Yeah, it's a NeurIPS podcast.
Alessio [00:00:32]: I think the two episodes are six hours, so there's plenty to listen, we'll make sure to send it over.
Swyx [00:00:37]: Yeah, we're trying this thing where at the major ML conferences, we, you know, do a little audio tour of, give people a sense of what it's like. But the last time you were on, you declared the end of fine tuning. I hope that I sort of editorialized the title a little bit, and I know you were slightly uncomfortable with it, but you just own it anyway. I think you're very good at the hot takes. And we were just discussing in our pre-show that it's really happening, that the continued pre-training is really happening.
Jeremy [00:01:02]: Yeah, absolutely. I think people are starting to understand that treating the three ULM FIT steps of like pre-training, you know, and then the kind of like what people now call instruction tuning, and then, I don't know if we've got a general term for this, DPO, RLHFE step, you know, or the task training, they're not actually as separate as we originally suggested they were in our paper, and when you treat it more as a continuum, and that you make sure that you have, you know, more of kind of the original data set incorporated into the later stages, and that, you know, we've also seen with LLAMA3, this idea that those later stages can be done for a lot longer. These are all of the things I was kind of trying to describe there. It wasn't the end of fine tuning, but more that we should treat it as a continuum, and we should have much higher expectations of how much you can do with an already trained model. You can really add a lot of behavior to it, you can change its behavior, you can do a lot. So a lot of our research has been around trying to figure out how to modify the model by a larger amount rather than starting from random weights, because I get very offended at the idea of starting from random weights.
Swyx [00:02:14]: Yeah, I saw that in ICLR in Vienna, there was an outstanding paper about starting transformers from data-driven piers. I don't know if you saw that one, they called it sort of never trained from scratch, and I think it was kind of rebelling against like the sort of random initialization.
Jeremy [00:02:28]: Yeah, I've, you know, that's been our kind of continuous message since we started Fast AI, is if you're training for random weights, you better have a really good reason, you know, because it seems so unlikely to me that nobody has ever trained on data that has any similarity whatsoever to the general class of data you're working with, and that's the only situation in which I think starting from random weights makes sense.
Swyx [00:02:51]: The other trends since our last pod that I would point people to is I'm seeing a rise in multi-phase pre-training. So Snowflake released a large model called Snowflake Arctic, where they detailed three phases of training where they had like a different mixture of like, there was like 75% web in the first instance, and then they reduced the percentage of the web text by 10% each time and increased the amount of code in each phase. And I feel like multi-phase is being called out in papers more. I feel like it's always been a thing, like changing data mix is not something new, but calling it a distinct phase is new, and I wonder if there's something that you're seeing
Jeremy [00:03:32]: on your end. Well, so they're getting there, right? So the point at which they're doing proper continued pre-training is the point at which that becomes a continuum rather than a phase. So the only difference with what I was describing last time is to say like, oh, there's a function or whatever, which is happening every batch. It's not a huge difference. You know, I always used to get offended when people had learning rates that like jumped. And so one of the things I started doing early on in Fast.ai was to say to people like, no, you should actually have your learning rate schedule should be a function, not a list of numbers. So now I'm trying to give the same idea about training mix.
Swyx [00:04:07]: There's been pretty public work from Meta on schedule-free optimizers. I don't know if you've been following Aaron DeFazio and what he's doing, just because you mentioned learning rate schedules, you know, what if you didn't have a schedule?
Jeremy [00:04:18]: I don't care very much, honestly. I don't think that schedule-free optimizer is that exciting. It's fine. We've had non-scheduled optimizers for ages, like Less Wright, who's now at Meta, who was part of the Fast.ai community there, created something called the Ranger optimizer. I actually like having more hyperparameters. You know, as soon as you say schedule-free, then like, well, now I don't get to choose. And there isn't really a mathematically correct way of, like, I actually try to schedule more parameters rather than less. So like, I like scheduling my epsilon in my atom, for example. I schedule all the things. But then the other thing we always did with the Fast.ai library was make it so you don't have to set any schedules. So Fast.ai always supported, like, you didn't even have to pass a learning rate. Like, it would always just try to have good defaults and do the right thing. But to me, I like to have more parameters I can play with if I want to, but you don't have to.
Alessio [00:05:08]: And then the more less technical side, I guess, of your issue, I guess, with the market was some of the large research labs taking all this innovation kind of behind closed doors and whether or not that's good, which it isn't. And now we could maybe make it more available to people. And then a month after we released the episode, there was the whole Sam Altman drama and like all the OpenAI governance issues. And maybe people started to think more, okay, what happens if some of these kind of labs, you know, start to break from within, so to speak? And the alignment of the humans is probably going to fall before the alignment of the models. So I'm curious, like, if you have any new thoughts and maybe we can also tie in some of the way that we've been building Answer as like a public benefit corp and some of those aspects.
Jeremy [00:05:51]: Sure. So, yeah, I mean, it was kind of uncomfortable because two days before Altman got fired, I did a small public video interview in which I said, I'm quite sure that OpenAI's current governance structure can't continue and that it was definitely going to fall apart. And then it fell apart two days later and a bunch of people were like, what did you know, Jeremy?
Alessio [00:06:13]: What did Jeremy see?
Jeremy [00:06:15]: I didn't see anything. It's just obviously true. Yeah. So my friend Eric Ries and I spoke a lot before that about, you know, Eric's, I think probably most people would agree, the top expert in the world on startup and AI governance. And you know, we could both clearly see that this didn't make sense to have like a so-called non-profit where then there are people working at a company, a commercial company that's owned by or controlled nominally by the non-profit, where the people in the company are being given the equivalent of stock options, like everybody there was working there with expecting to make money largely from their equity. So the idea that then a board could exercise control by saying like, oh, we're worried about safety issues and so we're going to do something that decreases the profit of the company, when every stakeholder in the company, their remuneration pretty much is tied to their profit, it obviously couldn't work. So I mean, that was a huge oversight there by someone. I guess part of the problem is that the kind of people who work at non-profits and in this case the board, you know, who are kind of academics and, you know, people who are kind of true believers. I think it's hard for them to realize that 99.999% of the world is driven very heavily by money, especially huge amounts of money. So yeah, Eric and I had been talking for a long time before that about what could be done differently, because also companies are sociopathic by design and so the alignment problem as it relates to companies has not been solved. Like, companies become huge, they devour their founders, they devour their communities and they do things where even the CEOs, you know, often of big companies tell me like, I wish our company didn't do that thing. You know, I know that if I didn't do it, then I would just get fired and the board would put in somebody else and the board knows if they don't do it, then their shareholders can sue them because they're not maximizing profitability or whatever. So what Eric's spent a lot of time doing is trying to think about how do we make companies less sociopathic, you know, how to, or more, you know, maybe a better way to think of it is like, how do we make it so that the founders of companies can ensure that their companies continue to actually do the things they want them to do? You know, when we started a company, hey, we very explicitly decided we got to start a company, not a academic lab, not a nonprofit, you know, we created a Delaware Seacorp, you know, the most company kind of company. But when we did so, we told everybody, you know, including our first investors, which was you Alessio. They sound great. We are going to run this company on the basis of maximizing long-term value. And in fact, so when we did our second round, which was an angel round, we had everybody invest through a long-term SPV, which we set up where everybody had to agree to vote in line with long-term value principles. So like never enough just to say to people, okay, we're trying to create long-term value here for society as well as for ourselves and everybody's like, oh, yeah, yeah, I totally agree with that. But when it comes to like, okay, well, here's a specific decision we have to make, which will not maximize short-term value, people suddenly change their mind. So you know, it has to be written into the legal documents of everybody so that no question that that's the way the company has to be managed. So then you mentioned the PBC aspect, Public Benefit Corporation, which I never quite understood previously. And turns out it's incredibly simple, like it took, you know, like one paragraph added to our corporate documents to become a PBC. It was cheap, it was easy, but it's got this huge benefit, which is if you're not a public benefit corporation, then somebody can come along and offer to buy you with a stated description of like turning your company into the thing you most hate, right? And if they offer you more than the market value of your company and you don't accept it, then you are not necessarily meeting the kind of your fiduciary responsibilities. So the way like Eric always described it to me is like, if Philip Morris came along and said that you've got great technology for marketing cigarettes to children, so we're going to pivot your company to do that entirely, and we're going to pay you 50% more than the market value, you're going to have to say yes. If you have a PBC, then you are more than welcome to say no, if that offer is not in line with your stated public benefit. So our stated public benefit is to maximize the benefit to society through using AI. So given that more children smoking doesn't do that, then we can say like, no, we're not selling to you.
Alessio [00:11:01]: I was looking back at some of our emails. You sent me an email on November 13th about talking and then on the 14th, I sent you an email working together to free AI was the subject line. And then that was kind of the start of the C round. And then two days later, someone got fired. So you know, you were having these thoughts even before we had like a public example of like why some of the current structures didn't work. So yeah, you were very ahead of the curve, so to speak. You know, people can read your awesome introduction blog and answer and the idea of having a R&D lab versus our lab and then a D lab somewhere else. I think to me, the most interesting thing has been hiring and some of the awesome people that you've been bringing on that maybe don't fit the central casting of Silicon Valley, so to speak. Like sometimes I got it like playing baseball cards, you know, people are like, oh, what teams was this person on, where did they work versus focusing on ability. So I would love for you to give a shout out to some of the awesome folks that you have on the team.
Jeremy [00:11:58]: So, you know, there's like a graphic going around describing like the people at XAI, you know, Elon Musk thing. And like they are all connected to like multiple of Stanford, Meta, DeepMind, OpenAI, Berkeley, Oxford. Look, these are all great institutions and they have good people. And I'm definitely not at all against that, but damn, there's so many other people. And one of the things I found really interesting is almost any time I see something which I think like this is really high quality work and it's something I don't think would have been built if that person hadn't built the thing right now, I nearly always reach out to them and ask to chat. And I tend to dig in to find out like, okay, you know, why did you do that thing? Everybody else has done this other thing, your thing's much better, but it's not what other people are working on. And like 80% of the time, I find out the person has a really unusual background. So like often they'll have like, either they like came from poverty and didn't get an opportunity to go to a good school or had dyslexia and, you know, got kicked out of school in year 11, or they had a health issue that meant they couldn't go to university or something happened in their past and they ended up out of the mainstream. And then they kind of succeeded anyway. Those are the people that throughout my career, I've tended to kind of accidentally hire more of, but it's not exactly accidentally. It's like when I see somebody who's done, two people who have done extremely well, one of them did extremely well in exactly the normal way from the background entirely pointing in that direction and they achieved all the hurdles to get there. And like, okay, that's quite impressive, you know, but another person who did just as well, despite lots of constraints and doing things in really unusual ways and came up with different approaches. That's normally the person I'm likely to find useful to work with because they're often like risk-takers, they're often creative, they're often extremely tenacious, they're often very open-minded. So that's the kind of folks I tend to find myself hiring. So now at Answer.ai, it's a group of people that are strong enough that nearly every one of them has independently come to me in the past few weeks and told me that they have imposter syndrome and they're not convinced that they're good enough to be here. And I kind of heard it at the point where I was like, okay, I don't think it's possible that all of you are so far behind your peers that you shouldn't get to be here. But I think part of the problem is as an R&D lab, the great developers look at the great researchers and they're like, wow, these big-brained, crazy research people with all their math and shit, they're too cool for me, oh my God. And then the researchers look at the developers and they're like, oh, they're killing it, making all this stuff with all these people using it and talking on Twitter about how great it is. I think they're both a bit intimidated by each other, you know. And so I have to kind of remind them like, okay, there are lots of things in this world where you suck compared to lots of other people in this company, but also vice versa, you know, for all things. And the reason you came here is because you wanted to learn about those other things from those other people and have an opportunity to like bring them all together into a single unit. You know, it's not reasonable to expect you're going to be better at everything than everybody else. I guess the other part of it is for nearly all of the people in the company, to be honest, they have nearly always been better than everybody else at nearly everything they're doing nearly everywhere they've been. So it's kind of weird to be in this situation now where it's like, gee, I can clearly see that I suck at this thing that I'm meant to be able to do compared to these other people where I'm like the worst in the company at this thing for some things. So I think that's a healthy place to be, you know, as long as you keep reminding each other about that's actually why we're here. And like, it's all a bit of an experiment, like we don't have any managers. We don't have any hierarchy from that point of view. So for example, I'm not a manager, which means I don't get to tell people what to do or how to do it or when to do it. Yeah, it's been a bit of an experiment to see how that would work out. And it's been great. So for instance, Ben Clavier, who you might have come across, he's the author of Ragatouille, he's the author of Rerankers, super strong information retrieval guy. And a few weeks ago, you know, this additional channel appeared on Discord, on our private Discord called Bert24. And these people started appearing, as in our collab sections, we have a collab section for like collaborating with outsiders. And these people started appearing, there are all these names that I recognize, like Bert24, and they're all talking about like the next generation of Bert. And I start following along, it's like, okay, Ben decided that I think, quite rightly, we need a new Bert. Because everybody, like so many people are still using Bert, and it's still the best at so many things, but it actually doesn't take advantage of lots of best practices. And so he just went out and found basically everybody who's created better Berts in the last four or five years, brought them all together, suddenly there's this huge collaboration going on. So yeah, I didn't tell him to do that. He didn't ask my permission to do that. And then, like, Benjamin Warner dived in, and he's like, oh, I created a whole transformers from scratch implementation designed to be maximally hackable. He originally did it largely as a teaching exercise to show other people, but he was like, I could, you know, use that to create a really hackable BERT implementation. In fact, he didn't say that. He said, I just did do that, you know, and I created a repo, and then everybody's like starts using it. They're like, oh my god, this is amazing. I can now implement all these other BERT things. And it's not just answer AI guys there, you know, there's lots of folks, you know, who have like contributed new data set mixes and blah, blah, blah. So, I mean, I can help in the same way that other people can help. So like, then Ben Clavier reached out to me at one point and said, can you help me, like, what have you learned over time about how to manage intimidatingly capable and large groups of people who you're nominally meant to be leading? And so, you know, I like to try to help, but I don't direct. Another great example was Kerem, who, after our FSTP QLORA work, decided quite correctly that it didn't really make sense to use LoRa in today's world. You want to use the normalized version, which is called Dora. Like two or three weeks after we did FSTP QLORA, he just popped up and said, okay, I've just converted the whole thing to Dora, and I've also created these VLLM extensions, and I've got all these benchmarks, and, you know, now I've got training of quantized models with adapters that are as fast as LoRa, and as actually better than, weirdly, fine tuning. Just like, okay, that's great, you know. And yeah, so the things we've done to try to help make these things happen as well is we don't have any required meetings, you know, but we do have a meeting for each pair of major time zones that everybody's invited to, and, you know, people see their colleagues doing stuff that looks really cool and say, like, oh, how can I help, you know, or how can I learn or whatever. So another example is Austin, who, you know, amazing background. He ran AI at Fidelity, he ran AI at Pfizer, he ran browsing and retrieval for Google's DeepMind stuff, created Jemma.cpp, and he's been working on a new system to make it easier to do web GPU programming, because, again, he quite correctly identified, yeah, so I said to him, like, okay, I want to learn about that. Not an area that I have much expertise in, so, you know, he's going to show me what he's working on and teach me a bit about it, and hopefully I can help contribute. I think one of the key things that's happened in all of these is everybody understands what Eric Gilliam, who wrote the second blog post in our series, the R&D historian, describes as a large yard with narrow fences. Everybody has total flexibility to do what they want. We all understand kind of roughly why we're here, you know, we agree with the premises around, like, everything's too expensive, everything's too complicated, people are building too many vanity foundation models rather than taking better advantage of fine-tuning, like, there's this kind of general, like, sense of we're all on the same wavelength about, you know, all the ways in which current research is fucked up, and, you know, all the ways in which we're worried about centralization. We all care a lot about not just research for the point of citations, but research that actually wouldn't have happened otherwise, and actually is going to lead to real-world outcomes. And so, yeah, with this kind of, like, shared vision, people understand, like, you know, so when I say, like, oh, well, you know, tell me, Ben, about BERT 24, what's that about? And he's like, you know, like, oh, well, you know, you can see from an accessibility point of view, or you can see from a kind of a actual practical impact point of view, there's far too much focus on decoder-only models, and, you know, like, BERT's used in all of these different places and industry, and so I can see, like, in terms of our basic principles, what we're trying to achieve, this seems like something important. And so I think that's, like, a really helpful that we have that kind of shared perspective, you know?
Alessio [00:21:14]: Yeah. And before we maybe talk about some of the specific research, when you're, like, reaching out to people, interviewing them, what are some of the traits, like, how do these things come out, you know, usually? Is it working on side projects that you, you know, you're already familiar with? Is there anything, like, in the interview process that, like, helps you screen for people that are less pragmatic and more research-driven versus some of these folks that are just gonna do it, you know? They're not waiting for, like, the perfect process.
Jeremy [00:21:40]: Everybody who comes through the recruiting is interviewed by everybody in the company. You know, our goal is 12 people, so it's not an unreasonable amount. So the other thing to say is everybody so far who's come into the recruiting pipeline, everybody bar one, has been hired. So which is to say our original curation has been good. And that's actually pretty easy, because nearly everybody who's come in through the recruiting pipeline are people I know pretty well. So Jono Whitaker and I, you know, he worked on the stable diffusion course we did. He's outrageously creative and talented, and he's super, like, enthusiastic tinkerer, just likes making things. Benjamin was one of the strongest parts of the fast.ai community, which is now the alumni. It's, like, hundreds of thousands of people. And you know, again, like, they're not people who a normal interview process would pick up, right? So Benjamin doesn't have any qualifications in math or computer science. Jono was living in Zimbabwe, you know, he was working on, like, helping some African startups, you know, but not FAANG kind of credentials. But yeah, I mean, when you actually see people doing real work and they stand out above, you know, we've got lots of Stanford graduates and open AI people and whatever in our alumni community as well. You know, when you stand out above all of those people anyway, obviously you've got something going for you. You know, Austin, him and I worked together on the masks study we did in the proceeding at the National Academy of Science. You know, we had worked together, and again, that was a group of, like, basically the 18 or 19 top experts in the world on public health and epidemiology and research design and so forth. And Austin, you know, one of the strongest people in that collaboration. So yeah, you know, like, I've been lucky enough to have had opportunities to work with some people who are great and, you know, I'm a very open-minded person, so I kind of am always happy to try working with pretty much anybody and some people stand out. You know, there have been some exceptions, people I haven't previously known, like Ben Clavier, actually, I didn't know before. But you know, with him, you just read his code, and I'm like, oh, that's really well-written code. And like, it's not written exactly the same way as everybody else's code, and it's not written to do exactly the same thing as everybody else's code. So yeah, and then when I chatted to him, it's just like, I don't know, I felt like we'd known each other for years, like we just were on the same wavelength, but I could pretty much tell that was going to happen just by reading his code. I think you express a lot in the code you choose to write and how you choose to write it, I guess. You know, or another example, a guy named Vic, who was previously the CEO of DataQuest, and like, in that case, you know, he's created a really successful startup. He won the first, basically, Kaggle NLP competition, which was automatic essay grading. He's got the current state-of-the-art OCR system, Surya. Again, he's just a guy who obviously just builds stuff, you know, he doesn't ask for permission, he doesn't need any, like, external resources. Actually, Karim's another great example of this, I mean, I already knew Karim very well because he was my best ever master's student, but it wasn't a surprise to me then when he then went off to create the world's state-of-the-art language model in Turkish on his own, in his spare time, with no budget, from scratch. This is not fine-tuning or whatever, he, like, went back to Common Crawl and did everything. Yeah, it's kind of, I don't know what I'd describe that process as, but it's not at all based on credentials.
Swyx [00:25:17]: Assemble based on talent, yeah. We wanted to dive in a little bit more on, you know, turning from the people side of things into the technical bets that you're making. Just a little bit more on Bert. I was actually, we just did an interview with Yi Tay from Reka, I don't know if you're familiar with his work, but also another encoder-decoder bet, and one of his arguments was actually people kind of over-index on the decoder-only GPT-3 type paradigm. I wonder if you have thoughts there that is maybe non-consensus as well. Yeah, no, absolutely.
Jeremy [00:25:45]: So I think it's a great example. So one of the people we're collaborating with a little bit with BERT24 is Colin Raffle, who is the guy behind, yeah, most of that stuff, you know, between that and UL2, there's a lot of really interesting work. And so one of the things I've been encouraging the BERT group to do, Colin has as well, is to consider using a T5 pre-trained encoder backbone as a thing you fine-tune, which I think would be really cool. You know, Colin was also saying actually just use encoder-decoder as your Bert, you know, why don't you like use that as a baseline, which I also think is a good idea. Yeah, look.
Swyx [00:26:25]: What technical arguments are people under-weighting?
Jeremy [00:26:27]: I mean, Colin would be able to describe this much better than I can, but I'll give my slightly non-expert attempt. Look, I mean, think about like diffusion models, right? Like in stable diffusion, like we use things like UNet. You have this kind of downward path and then in the upward path you have the cross connections, which it's not a tension, but it's like a similar idea, right? You're inputting the original encoding path into your decoding path. It's critical to make it work, right? Because otherwise in the decoding part, the model has to do so much kind of from scratch. So like if you're doing translation, like that's a classic kind of encoder-decoder example. If it's decoder only, you never get the opportunity to find the right, you know, feature engineering, the right feature encoding for the original sentence. And it kind of means then on every token that you generate, you have to recreate the whole thing, you know? So if you have an encoder, it's basically saying like, okay, this is your opportunity model to create a really useful feature representation for your input information. So I think there's really strong arguments for encoder-decoder models anywhere that there is this kind of like context or source thing. And then why encoder only? Well, because so much of the time what we actually care about is a classification, you know? It's like an output. It's like generating an arbitrary length sequence of tokens. So anytime you're not generating an arbitrary length sequence of tokens, decoder models don't seem to make much sense. Now the interesting thing is, you see on like Kaggle competitions, that decoder models still are at least competitive with things like Deberta v3. They have to be way bigger to be competitive with things like Deberta v3. And the only reason they are competitive is because people have put a lot more time and money and effort into training the decoder only ones, you know? There isn't a recent Deberta. There isn't a recent Bert. Yeah, it's a whole part of the world that people have slept on a little bit. And this is just what happens. This is how trends happen rather than like, to me, everybody should be like, oh, let's look at the thing that has shown signs of being useful in the past, but nobody really followed up with properly. That's the more interesting path, you know, where people tend to be like, oh, I need to get citations. So what's everybody else doing? Can I make it 0.1% better, you know, or 0.1% faster? That's what everybody tends to do. Yeah. So I think it's like, Itay's work commercially now is interesting because here's like a whole, here's a whole model that's been trained in a different way. So there's probably a whole lot of tasks it's probably better at than GPT and Gemini and Claude. So that should be a good commercial opportunity for them if they can figure out what those tasks are.
Swyx [00:29:07]: Well, if rumors are to be believed, and he didn't comment on this, but, you know, Snowflake may figure out the commercialization for them. So we'll see.
Jeremy [00:29:14]: Good.
Alessio [00:29:16]: Let's talk about FSDP, Qlora, Qdora, and all of that awesome stuff. One of the things we talked about last time, some of these models are meant to run on systems that nobody can really own, no single person. And then you were like, well, what if you could fine tune a 70B model on like a 4090? And I was like, no, that sounds great, Jeremy, but like, can we actually do it? And then obviously you all figured it out. Can you maybe tell us some of the worst stories behind that, like the idea behind FSDP, which is kind of taking sharded data, parallel computation, and then Qlora, which is do not touch all the weights, just go quantize some of the model, and then within the quantized model only do certain layers instead of doing everything.
Jeremy [00:29:57]: Well, do the adapters. Yeah.
Alessio [00:29:59]: Yeah. Yeah. Do the adapters. Yeah. I will leave the floor to you. I think before you published it, nobody thought this was like a short term thing that we're just going to have. And now it's like, oh, obviously you can do it, but it's not that easy.
Jeremy [00:30:12]: Yeah. I mean, to be honest, it was extremely unpleasant work to do. It's like not at all enjoyable. I kind of did version 0.1 of it myself before we had launched the company, or at least the kind of like the pieces. They're all pieces that are difficult to work with, right? So for the quantization, you know, I chatted to Tim Detmers quite a bit and, you know, he very much encouraged me by saying like, yeah, it's possible. He actually thought it'd be easy. It probably would be easy for him, but I'm not Tim Detmers. And, you know, so he wrote bits and bytes, which is his quantization library. You know, he wrote that for a paper. He didn't write that to be production like code. It's now like everybody's using it, at least the CUDA bits. So like, it's not particularly well structured. There's lots of code paths that never get used. There's multiple versions of the same thing. You have to try to figure it out. So trying to get my head around that was hard. And you know, because the interesting bits are all written in CUDA, it's hard to like to step through it and see what's happening. And then, you know, FSTP is this very complicated library and PyTorch, which not particularly well documented. So the only really, really way to understand it properly is again, just read the code and step through the code. And then like bits and bytes doesn't really work in practice unless it's used with PEF, the HuggingFace library and PEF doesn't really work in practice unless you use it with other things. And there's a lot of coupling in the HuggingFace ecosystem where like none of it works separately. You have to use it all together, which I don't love. So yeah, trying to just get a minimal example that I can play with was really hard. And so I ended up having to rewrite a lot of it myself to kind of create this like minimal script. One thing that helped a lot was Medec had this LlamaRecipes repo that came out just a little bit before I started working on that. And like they had a kind of role model example of like, here's how to train FSTP, LoRa, didn't work with QLoRa on Llama. A lot of the stuff I discovered, the interesting stuff would be put together by Les Wright, who's, he was actually the guy in the Fast.ai community I mentioned who created the Ranger Optimizer. So he's doing a lot of great stuff at Meta now. So yeah, I kind of, that helped get some minimum stuff going and then it was great once Benjamin and Jono joined full time. And so we basically hacked at that together and then Kerim joined like a month later or something. And it was like, gee, it was just a lot of like fiddly detailed engineering on like barely documented bits of obscure internals. So my focus was to see if it kind of could work and I kind of got a bit of a proof of concept working and then the rest of the guys actually did all the work to make it work properly. And, you know, every time we thought we had something, you know, we needed to have good benchmarks, right? So we'd like, it's very easy to convince yourself you've done the work when you haven't, you know, so then we'd actually try lots of things and be like, oh, and these like really important cases, the memory use is higher, you know, or it's actually slower. And we'd go in and we just find like all these things that were nothing to do with our library that just didn't work properly. And nobody had noticed they hadn't worked properly because nobody had really benchmarked it properly. So we ended up, you know, trying to fix a whole lot of different things. And even as we did so, new regressions were appearing in like transformers and stuff that Benjamin then had to go away and figure out like, oh, how come flash attention doesn't work in this version of transformers anymore with this set of models and like, oh, it turns out they accidentally changed this thing, so it doesn't work. You know, there's just, there's not a lot of really good performance type evals going on in the open source ecosystem. So there's an extraordinary amount of like things where people say like, oh, we built this thing and it has this result. And when you actually check it, so yeah, there's a shitload of war stories from getting that thing to work. And it did require a particularly like tenacious group of people and a group of people who don't mind doing a whole lot of kind of like really janitorial work, to be honest, to get the details right, to check them. Yeah.
Alessio [00:34:09]: We had a trade out on the podcast and we talked about how a lot of it is like systems work to make some of these things work. It's not just like beautiful, pure math that you do on a blackboard. It's like, how do you get into the nitty gritty?
Jeremy [00:34:22]: I mean, flash attention is a great example of that. Like it's, it basically is just like, oh, let's just take the attention and just do the tiled version of it, which sounds simple enough, you know, but then implementing that is challenging at lots of levels.
Alessio [00:34:36]: Yeah. What about inference? You know, obviously you've done all this amazing work on fine tuning. Do you have any research you've been doing on the inference side, how to make local inference really fast on these models too?
Jeremy [00:34:47]: We're doing quite a bit on that at the moment. We haven't released too much there yet. But one of the things I've been trying to do is also just to help other people. And one of the nice things that's happened is that a couple of folks at Meta, including Mark Saroufim, have done a nice job of creating this CUDA mode community of people working on like CUDA kernels or learning about that. And I tried to help get that going well as well and did some lessons to help people get into it. So there's a lot going on in both inference and fine tuning performance. And a lot of it's actually happening kind of related to that. So PyTorch team have created this Torch AO project on quantization. And so there's a big overlap now between kind of the FastAI and AnswerAI and CUDA mode communities of people working on stuff for both inference and fine tuning. But we're getting close now. You know, our goal is that nobody should be merging models, nobody should be downloading merged models, everybody should be using basically quantized plus adapters for almost everything and just downloading the adapters. And that should be much faster. So that's kind of the place we're trying to get to. It's difficult, you know, because like Karim's been doing a lot of work with VLM, for example. These inference engines are pretty complex bits of code. They have a whole lot of custom kernel stuff going on as well, as do the quantization libraries. So we've been working on, we're also quite a bit of collaborating with the folks who do HQQ, which is a really great quantization library and works super well. So yeah, there's a lot of other people outside AnswerAI that we're working with a lot who are really helping on all this performance optimization stuff, open source.
Swyx [00:36:27]: Just to follow up on merging models, I picked up there that you said nobody should be merging models. That's interesting because obviously a lot of people are experimenting with this and finding interesting results. I would say in defense of merging models, you can do it without data. That's probably the only thing that's going for it.
Jeremy [00:36:45]: To explain, it's not that you shouldn't merge models. You shouldn't be distributing a merged model. You should distribute a merged adapter 99% of the time. And actually often one of the best things happening in the model merging world is actually that often merging adapters works better anyway. The point is, Sean, that once you've got your new model, if you distribute it as an adapter that sits on top of a quantized model that somebody's already downloaded, then it's a much smaller download for them. And also the inference should be much faster because you're not having to transfer FB16 weights from HPM memory at all or ever load them off disk. You know, all the main weights are quantized and the only floating point weights are in the adapters. So that should make both inference and fine tuning faster. Okay, perfect.
Swyx [00:37:33]: We're moving on a little bit to the rest of the fast universe. I would have thought that, you know, once you started Answer.ai, that the sort of fast universe would be kind of on hold. And then today you just dropped Fastlight and it looks like, you know, there's more activity going on in sort of Fastland.
Jeremy [00:37:49]: Yeah. So Fastland and Answerland are not really distinct things. Answerland is kind of like the Fastland grown up and funded. They both have the same mission, which is to maximize the societal benefit of AI broadly. We want to create thousands of commercially successful products at Answer.ai. And we want to do that with like 12 people. So that means we need a pretty efficient stack, you know, like quite a few orders of magnitude more efficient, not just for creation, but for deployment and maintenance than anything that currently exists. People often forget about the D part of our R&D firm. So we've got to be extremely good at creating, deploying and maintaining applications, not just models. Much to my horror, the story around creating web applications is much worse now than it was 10 or 15 years ago in terms of, if I say to a data scientist, here's how to create and deploy a web application, you know, either you have to learn JavaScript or TypeScript and about all the complex libraries like React and stuff, and all the complex like details around security and web protocol stuff around how you then talk to a backend and then all the details about creating the backend. You know, if that's your job and, you know, you have specialists who work in just one of those areas, it is possible for that to all work. But compared to like, oh, write a PHP script and put it in the home directory that you get when you sign up to this shell provider, which is what it was like in the nineties, you know, here are those 25 lines of code and you're done and now you can pass that URL around to all your friends, or put this, you know, .pl file inside the CGI bin directory that you got when you signed up to this web host. So yeah, the thing I've been mainly working on the last few weeks is fixing all that. And I think I fixed it. I don't know if this is an announcement, but I tell you guys, so yeah, there's this thing called fastHTML, which basically lets you create a complete web application in a single Python file. Unlike excellent projects like Streamlit and Gradio, you're not working on top of a highly abstracted thing. That's got nothing to do with web foundations. You're working with web foundations directly, but you're able to do it by using pure Python. There's no template, there's no ginger, there's no separate like CSS and JavaScript files. It looks and behaves like a modern SPA web application. And you can create components for like daisy UI, or bootstrap, or shoelace, or whatever fancy JavaScript and or CSS tailwind etc library you like, but you can write it all in Python. You can pip install somebody else's set of components and use them entirely from Python. You can develop and prototype it all in a Jupyter notebook if you want to. It all displays correctly, so you can like interactively do that. And then you mentioned Fastlight, so specifically now if you're using SQLite in particular, it's like ridiculously easy to have that persistence, and all of your handlers will be passed database ready objects automatically, that you can just call dot delete dot update dot insert on. Yeah, you get session, you get security, you get all that. So again, like with most everything I do, it's very little code. It's mainly tying together really cool stuff that other people have written. You don't have to use it, but a lot of the best stuff comes from its incorporation of HTMX, which to me is basically the thing that changes your browser to make it work the way it always should have. So it just does four small things, but those four small things are the things that are basically unnecessary constraints that HTML should never have had, so it removes the constraints. It sits on top of Starlet, which is a very nice kind of lower level platform for building these kind of web applications. The actual interface matches as closely as possible to FastAPI, which is a really nice system for creating the kind of classic JavaScript type applications. And Sebastian, who wrote FastAPI, has been kind enough to help me think through some of these design decisions, and so forth. I mean, everybody involved has been super helpful. Actually, I chatted to Carson, who created HTMX, you know, so about it. Some of the folks involved in Django, like everybody in the community I've spoken to definitely realizes there's a big gap to be filled around, like, highly scalable, web foundation-based, pure Python framework with a minimum of fuss. So yeah, I'm getting a lot of support and trying to make sure that FastHTML works well for people.
Swyx [00:42:38]: I would say, when I heard about this, I texted Alexio. I think this is going to be pretty huge. People consider Streamlit and Gradio to be the state of the art, but I think there's so much to improve, and having what you call web foundations and web fundamentals at the core of it, I think, would be really helpful.
Jeremy [00:42:54]: I mean, it's based on 25 years of thinking and work for me. So like, FastML was built on a system much like this one, but that was of hell. And so I spent, you know, 10 years working on that. We had millions of people using that every day, really pushing it hard. And I really always enjoyed working in that. Yeah. So, you know, and obviously lots of other people have done like great stuff, and particularly HTMX. So I've been thinking about like, yeah, how do I pull together the best of the web framework I created for FastML with HTMX? There's also things like PicoCSS, which is the CSS system, which by default, FastHTML comes with. Although, as I say, you can pip install anything you want to, but it makes it like super easy to, you know, so we try to make it so that just out of the box, you don't have any choices to make. Yeah. You can make choices, but for most people, you just, you know, it's like the PHP in your home directory thing. You just start typing and just by default, you'll get something which looks and feels, you know, pretty okay. And if you want to then write a version of Gradio or Streamlit on top of that, you totally can. And then the nice thing is if you then write it in kind of the Gradio equivalent, which will be, you know, I imagine we'll create some kind of pip installable thing for that. Once you've outgrown, or if you outgrow that, it's not like, okay, throw that all away and start again. And this like whole separate language that it's like this kind of smooth, gentle path that you can take step-by-step because it's all just standard web foundations all the way, you know.
Swyx [00:44:29]: Just to wrap up the sort of open source work that you're doing, you're aiming to create thousands of projects with a very, very small team. I haven't heard you mention once AI agents or AI developer tooling or AI code maintenance. I know you're very productive, but you know, what is the role of AI in your own work?
Jeremy [00:44:47]: So I'm making something. I'm not sure how much I want to say just yet.
Swyx [00:44:52]: Give us a nibble.
Jeremy [00:44:53]: All right. I'll give you the key thing. So I've created a new approach. It's not called prompt engineering. It's called dialogue engineering. But I'm creating a system for doing dialogue engineering. It's currently called AI magic. I'm doing most of my work in this system and it's making me much more productive than I was before I used it. So I always just build stuff for myself and hope that it'll be useful for somebody else. Think about chat GPT with code interpreter, right? The basic UX is the same as a 1970s teletype, right? So if you wrote APL on a teletype in the 1970s, you typed onto a thing, your words appeared at the bottom of a sheet of paper and you'd like hit enter and it would scroll up. And then the answer from APL would be printed out, scroll up, and then you would type the next thing. And like, which is also the way, for example, a shell works like bash or ZSH or whatever. It's not terrible, you know, like we all get a lot done in these like very, very basic teletype style REPL environments, but I've never felt like it's optimal and everybody else has just copied chat GPT. So it's also the way BART and Gemini work. It's also the way the Claude web app works. And then you add code interpreter. And the most you can do is to like plead with chat GPT to write the kind of code I want. It's pretty good for very, very, very beginner users who like can't code at all, like by default now the code's even hidden away, so you never even have to see it ever happened. But for somebody who's like wanting to learn to code or who already knows a bit of code or whatever, it's, it seems really not ideal. So okay, that's one end of the spectrum. The other end of the spectrum, which is where Sean's work comes in, is, oh, you want to do more than chat GPT? No worries. Here is Visual Studio Code. I run it. There's an empty screen with a flashing cursor. Okay, start coding, you know, and it's like, okay, you can use systems like Sean's or like cursor or whatever to be like, okay, Apple K in cursors, like a creative form that blah, blah, blah. But in the end, it's like a convenience over the top of this incredibly complicated system that full-time sophisticated software engineers have designed over the past few decades in a totally different environment as a way to build software, you know. And so we're trying to like shoehorn in AI into that. And it's not easy to do. And I think there are like much better ways of thinking about the craft of software development in a language model world to be much more interactive, you know. So the thing that I'm building is neither of those things. It's something between the two. And it's built around this idea of crafting a dialogue, you know, where the outcome of the dialogue is the artifacts that you want, whether it be a piece of analysis or whether it be a Python library or whether it be a technical blog post or whatever. So as part of building that, I've created something called Claudette, which is a library for Claude. I've created something called Cosette, which is a library for OpenAI. They're libraries which are designed to make those APIs much more usable, much easier to use, much more concise. And then I've written AI magic on top of those. And that's been an interesting exercise because I did Claudette first, and I was looking at what Simon Willison did with his fantastic LLM library. And his library is designed around like, let's make something that supports all the LLM inference engines and commercial providers. I thought, okay, what if I did something different, which is like make something that's as Claude friendly as possible and forget everything else. So that's what Claudette was. So for example, one of the really nice things in Claude is prefill. So by telling the assistant that this is what your response started with, there's a lot of powerful things you can take advantage of. So yeah, I created Claudette to be as Claude friendly as possible. And then after I did that, and then particularly with GPT 4.0 coming out, I kind of thought, okay, now let's create something that's as OpenAI friendly as possible. And then I tried to look to see, well, where are the similarities and where are the differences? And now can I make them compatible in places where it makes sense for them to be compatible without losing out on the things that make each one special for what they are. So yeah, those are some of the things I've been working on in that space. And I'm thinking we might launch AI magic via a course called how to solve it with code. The name is based on the classic Polya book, if you know how to solve it, which is, you know, one of the classic math books of all time, where we're basically going to try to show people how to solve challenging problems that they didn't think they could solve without doing a full computer science course, by taking advantage of a bit of AI and a bit of like practical skills, as particularly for this like whole generation of people who are learning to code with and because of ChatGPT. Like I love it, I know a lot of people who didn't really know how to code, but they've created things because they use ChatGPT, but they don't really know how to maintain them or fix them or add things to them that ChatGPT can't do, because they don't really know how to code. And so this course will be designed to show you how you can like either become a developer who can like supercharge their capabilities by using language models, or become a language model first developer who can supercharge their capabilities by understanding a bit about process and fundamentals.
Alessio [00:50:19]: Nice. That's a great spoiler. You know, I guess the fourth time you're going to be on learning space, we're going to talk about AI magic. Jeremy, before we wrap, this was just a great run through everything. What are the things that when you next come on the podcast in nine, 12 months, we're going to be like, man, Jeremy was like really ahead of it. Like, is there anything that you see in the space that maybe people are not talking enough? You know, what's the next company that's going to fall, like have drama internally, anything in your mind?
Jeremy [00:50:47]: You know, hopefully we'll be talking a lot about fast HTML and hopefully the international community that at that point has come up around that. And also about AI magic and about dialogue engineering. Hopefully dialogue engineering catches on because I think it's the right way to think about a lot of this stuff. What else? Just trying to think about all on the research side. Yeah. I think, you know, I mean, we've talked about a lot of it. Like I think encoder decoder architectures, encoder only architectures, hopefully we'll be talking about like the whole re-interest in BERT that BERT 24 stimulated.
Swyx [00:51:17]: There's a safe space model that came out today that might be interesting for this general discussion. One thing that stood out to me with Cartesia's blog posts was that they were talking about real time ingestion, billions and trillions of tokens, and keeping that context, obviously in the state space that they have.
Jeremy [00:51:34]: Yeah.
Swyx [00:51:35]: I'm wondering what your thoughts are because you've been entirely transformers the whole time.
Jeremy [00:51:38]: Yeah. No. So obviously my background is RNNs and LSTMs. Of course. And I'm still a believer in the idea that state is something you can update, you know? So obviously Sepp Hochreiter came up, came out with xLSTM recently. Oh my God. Okay. Another whole thing we haven't talked about, just somewhat related. I've been going crazy for like a long time about like, why can I not pay anybody to save my KV cash? I just ingested the Great Gatsby or the documentation for Starlet or whatever, you know, I'm sending it as my prompt context. Why are you redoing it every time? So Gemini is about to finally come out with KV caching, and this is something that Austin actually in Gemma.cpp had had on his roadmap for years, well not years, months, long time. The idea that the KV cache is like a thing that, it's a third thing, right? So there's RAG, you know, there's in-context learning, you know, and prompt engineering, and there's KV cache creation. I think it creates like a whole new class almost of applications or as techniques where, you know, for me, for example, I very often work with really new libraries or I've created my own library that I'm now writing with rather than on. So I want all the docs in my new library to be there all the time. So I want to upload them once, and then we have a whole discussion about building this application using FastHTML. Well nobody's got FastHTML in their language model yet, I don't want to send all the FastHTML docs across every time. So one of the things I'm looking at doing in AI Magic actually is taking advantage of some of these ideas so that you can have the documentation of the libraries you're working on be kind of always available. Something over the next 12 months people will be spending time thinking about is how to like, where to use RAG, where to use fine-tuning, where to use KV cache storage, you know. And how to use state, because in state models and XLSTM, again, state is something you update. So how do we combine the best of all of these worlds?
Alessio [00:53:46]: And Jeremy, I know before you talked about how some of the autoregressive models are not maybe a great fit for agents. Any other thoughts on like JEPA, diffusion for text, any interesting thing that you've seen pop up?
Jeremy [00:53:58]: In the same way that we probably ought to have state that you can update, i.e. XLSTM and state models, in the same way that a lot of things probably should have an encoder, JEPA and diffusion both seem like the right conceptual mapping for a lot of things we probably want to do. So the idea of like, there should be a piece of the generative pipeline, which is like thinking about the answer and coming up with a sketch of what the answer looks like before you start outputting tokens. That's where it kind of feels like diffusion ought to fit, you know. And diffusion is, because it's not autoregressive, it's like, let's try to like gradually de-blur the picture of how to solve this. So this is also where dialogue engineering fits in, by the way. So with dialogue engineering, one of the reasons it's working so well for me is I use it to kind of like craft the thought process before I generate the code, you know. So yeah, there's a lot of different pieces here and I don't know how they'll all kind of exactly fit together. I don't know if JEPA is going to actually end up working in the text world. I don't know if diffusion will end up working in the text world, but they seem to be like trying to solve a class of problem which is currently unsolved.
Alessio [00:55:13]: Awesome, Jeremy. This was great, as usual. Thanks again for coming back on the pod and thank you all for listening. Yeah, that was fantastic.
86 つのエピソード



